Co-processor
Offloading
Applied
to Passive Coherent Location
With
Doppler and Bearing Data
Joseph
Milburn Masters Dissertation
AIM: To
accelerate a filtering algorithm for tracking aircraft by offloading key computationally
expensive sections to a custom hardware architecture coprocessor
Filtering
Algorithm:
The
algorithm, developed by Dr Norman Morrison, uses non-linear differential
correction to develop a state vector for a target using doppler and bearing
data as input.
The
algorithm is suitable for use with a low cost Passive Coherent Location (PCL)
system. PCL radar systems have low procurement, operation and maintenance costs
as they substitute high cost hardware with algorithmic complexity. This is of particular
benefit when deployed for aircraft traffic control in 3rd world
African countries. Many African airports lack radar assisted air traffic
control, which is a contributing factor to Africa's high aircraft accident to
flying hours ratio, the highest in the world.
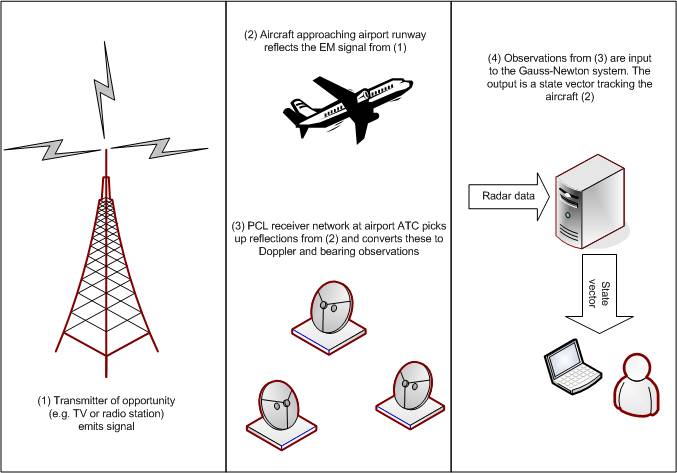
Air
Traffic control with a PCL system
The doppler and bearing input is fed into an Expanding Memory
Polynomial filter of degree 1 for initialization. EMP filtering finds the
straight line that best fits the observations in the sense of least squares. An
initial state vector is developed from the smoothed data, specifying the
aircraft's position and velocity in two dimensions.
After initialization, control is passed to the differential
correction algorithm. The algorithm uses the following inputs:
·
Y(n): a set of radar observations (doppler and
bearing) gathered over time by a network of receivers.
·
rcvr_fd_σ and rcvr_ψ_σ : the
observation variable variances for each receiver
·
Xbar and Xbardot: the initial
approximation to the state vector from track initialization
·
Φ(n,n-1): a transition matrix translating state
between time instances where: Xn = Φ(n,n-1) . Xn-1
Differential
correction combines data from a number of radar receivers using the minimum variance
rule. New data is incorporated as it is received in order to continually
correct the model in an optimal fashion. The model produced by is a polynomial
which describes the trajectory of the aircraft in 3dimensions.
The algorithm is
computationally intensive and involves high dimension matrix-matrix
multiplication.
Research
objectives:
·
Identify the most computationally intensive areas of the
algorithm.
·
Port the algorithm to a hardware platform with a High
Performance Computing (HPC) component
·
Test the performance of the algorithm on the HPC system as
compared to the base system
Hardware
and Implementation:
The traditional method of increasing computing performance by
increasing clock speed and transistor density of a von Neumann architecture CPU
is now facing a brick wall limit. This limit is both in terms of the physical
size of transistor technology and clock speed due to excessive power
consumption and heat dissipation. Therefore innovations in computer
architecture must substitute for the traditional method. One approach to
increasing compute performance that has received attention in recent times is
the use of co-processor accelerator boards. These boards offer dramatic power
and space benefits over other forms of HPC while offering impressive
performance increases over conventional serial computing architectures.
The
co-processor used for this project was the ClearSpeed Advance e620 accelerator
board, which fits into the PCIExpress (PCIe)
slot of a conventional computing platform. The e620 is said to be the fastest
and most power efficient double-precision 64-bit floating point processor in
the world. The e620 consists of two CSX600 embedded parallel processors
communicating via the ClearConnect busbridge ports. One CSX600 contains 96 execution
cores or processing elements (PEs), each of which is
a Very
Long Instruction Word (VLIW) core. The card has 1GB of local DDR2-400 SDRAM
shared between the two CSX600s via a common 32 or 64 bit address space. On one
end of the ClearConnect bus is an FPGA which implements the host interface
which may be changed for performance or functionality upgrades. Under standard
operation the board is capable of 50GFLOPS of sustained performance and draws
25W which illustrates its impressive performance per watt metric. The card
costs around US$8000 before volume discounts.
The
CSX600 processor It is programmed in C, and supports Level 3 BLAS, FFTW and
LAPACK. Code is enabled to run on the CSX600 by making Clearspeed library
function calls. The runtime environment of the Clearspeed software package uses
heuristics to determine how to split processing between the host CPU and the
advance accelerator card.
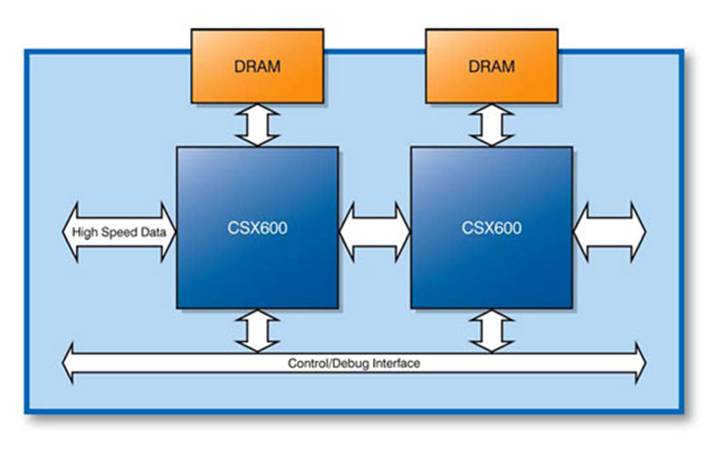
Clearspeed
Advance architecture block diagram (www.clearspeed.com)
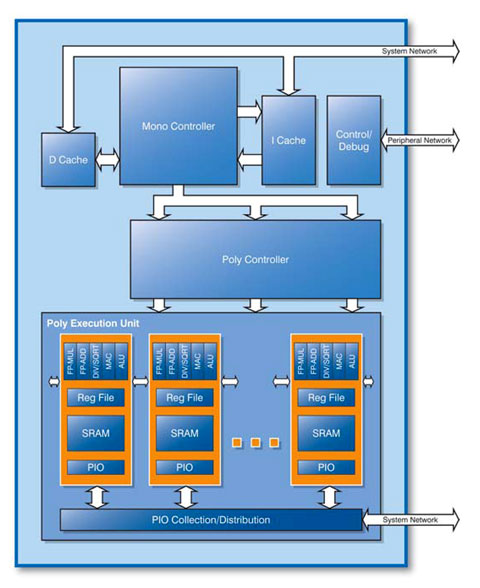
CSX600
MTAP architecture (www.clearspeed.com)
The
hardware being used is installed at the Centre for High Performance Computing
(CHPC), a division of the Council for Scientific Research (CSIR) in South
Africa.
Links:
Radar Remote
Sensing Group
Department of
Electrical Engineering
University of Cape
Town
Contact
Details:
Joseph Milburn
Email: joetendai@gmail.com
CHPC Contact:
CSIR Campus
Lower Hope St.
Rosebank
Cape Town
South Africa
Rosebank 7700
Phone: 021 658 2758
RRSG Contact:
Room 6.17 Menzies 6th
floor
Radar Remote
Sensing Group
Department of
Electrical Engineering
University of Cape
Town
Private Bag
Rondebosch 7701
South Africa
Phone: +27 (0)21 650 3756